- Results -





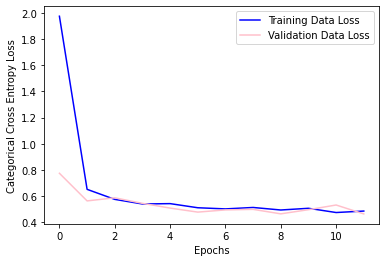
Loss Over Training Epochs


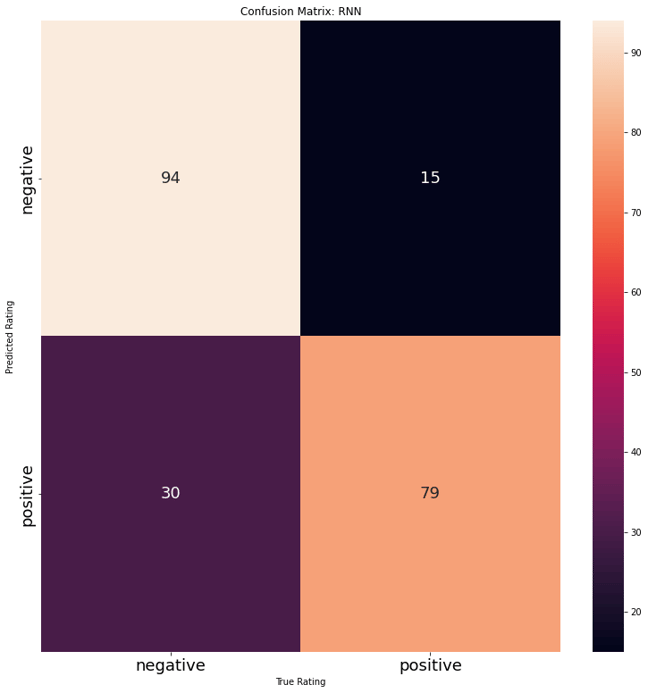
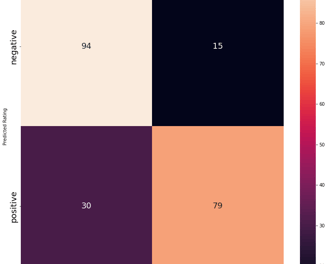
Model Evaluation
Reviews for California State University San Marcos were gathered to test the model on. There were 109 positive reviews and 109 negative reviews. The model performed fairly well in classifying the texts. The model seemed to have a higher tendency to misclassify Negative reviews as positive. A closer look at some of the misclassified text shows how many comments contain positive and negative comments about the university. This can make it difficult to classify and often the presence of a certain word (or not) can push the review over to the wrong label. This is one of the aspects that makes sentiment analyses of reviews difficult. Often there are reviews on each end of either extreme love or extreme hate and then a majority of evaluations stand in the middle- with students sharing both likes and dislikes.