DECISION TREE
A decision tree is a popular machine learning algorithm used for both classification and regression tasks. Unlike many other ML models, the results are visualized in a fairly intuitive tree-like graphic that can be simpler for non-technical audiences to interpret. The general structure consists of "internal nodes" representing a feature or attribute, connecting branches representing a decision (or split), and leaf nodes representing an outcome or prediction. The model works by partitioning or "splitting" data until it is classified. The general process is:
Data Splitting: The decision tree algorithm starts by selecting the most important feature from the dataset to act as the "root node." This feature is chosen based on criteria such as information gain: "Entropy" or node impurity: "Gini."
Feature Splitting: The selected feature is used to split the dataset into subsets based on its possible values. Each subset corresponds to a different branch extending from the root node.
Recursive Splitting: The splitting process is repeated for each subset, creating additional internal nodes and branches. This repeated splitting continues until a stopping criterion is met (often given by a purity value or tree depth limit)
Leaf Node Assignment: Once the tree has been constructed, each leaf node is assigned a class label or predicted value. This assignment depends on the majority class or the mean/median value of the samples within the leaf node
Prediction: To make predictions for new, unseen data, the input data follows the decision tree path from the root to a specific leaf node based on the feature values. The assigned class label or predicted value of that leaf node is then used as the final prediction.
Although decision trees offer several advantages (such as interpretability and insight into feature importance), they can also lead to overfitting due to massive or overly-complex trees. Parameter tuning and placing manual limitations on the tree can help eliminate or further cause this issue. Similarly, decision trees can become massive with high dimensional data such as text data. Ensembles (i.e. groups of multiple trees) such as Random Forests can be used to produce multiple decision trees and make more accurate and robust predictions.
GMO Perception
The data taken from the Study on Perceived Subjective vs Objective Knowledge of GM Crops discussed in greater detail on the Naive Bayes page was split into balanced Traing and Testing data.
The goal is to use decision trees to predict an individuals likelihood to choose/purchase GMO crops in the presence of non-GMO options based on the following demographic and labeling attributes:




Plant type - the type of fruit tree or plant variety
Heirloom - branding indicating age-old plant varieties
Income - Average income of individual
Price - purchasing cost of the plant
Age - age of individual being surveyed
Sex - biological sex of individual being surveyed
Household size - number of individuals (kids+adults) in surveyed individual’s household
Education - education level on scale 1 to 5 (level values unknown)
Ethnicity - ethnicity of individual represented by value 1-6 (ethnicities unknown)
Veriflora - branding indicating sustainable growing practices
Objective knowledge - individuals knowledge of GMO’s according to 3-question quiz
Subjective knowledge - individuals self declared (I.e. perceived) knowledge of GMO’s
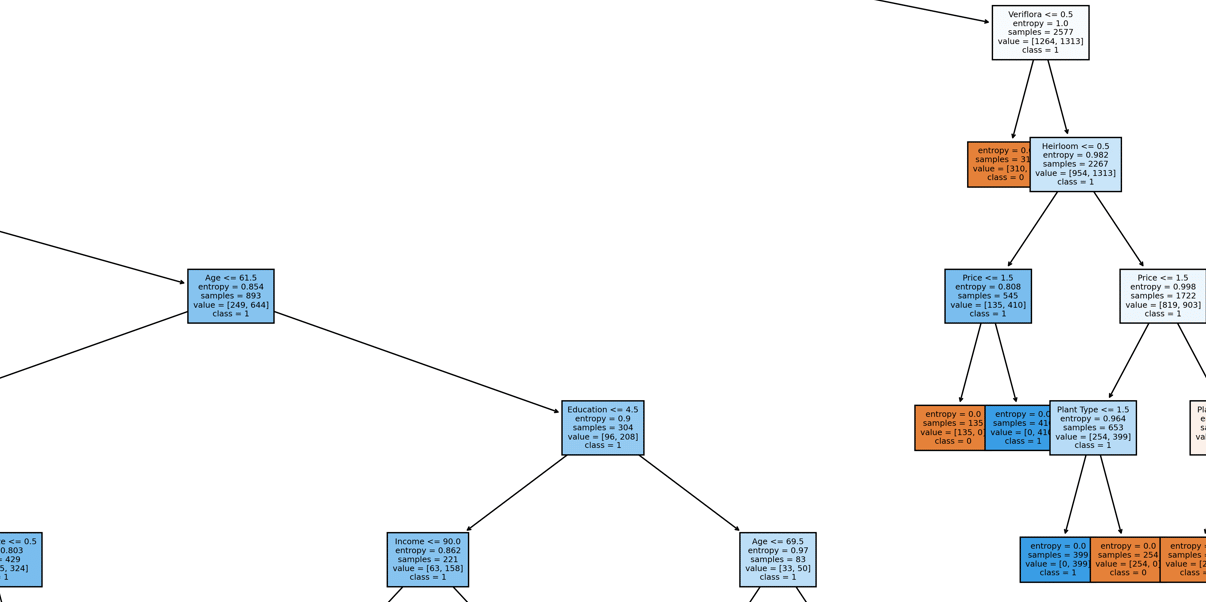

Decision Tree
NOTE: Click on the decision tree to open an external graphic that can be zoomed-in to show clear, readable results


The Decision Tree above (which is limited to a max depth of 10) predicts the data considerably well:
77% Accuracy
Results
Despite the poor performance of Naive Bayes on the perception data, an unbounded Decision Tree classifier model was able to predict with accuracy in the 80% range. However, the unbounded b=model produced a tree that was nearly impossible to read or trace value from. Therefore, the tree was limited to 10 levels which resulted in far more interpretable results with considerably low accuracy sacrifice.
The graphic following indicates the importance of each feature in determining GMO choice. Suggesting that plant type and price significantly impact wether an individual opts to purchase GMO containing plants or not.